Fig. 10.1. The example of DRT (Logan et al. 1989).
10. Speech Quality and Evaluation
Synthetic speech can be compared and evaluated with respect to intelligibility, naturalness, and suitability for used application (Klatt 1987, Mariniak 1993). In some applications, for example reading machines for the blind, the speech intelligibility with high speech rate is usually more important feature than the naturalness. On the other hand, prosodic features and naturalness are essential when we are dealing with multimedia applications or electronic mail readers. The evaluation can also be made at several levels, such as phoneme, word or sentence level, depending what kind of information is needed.
Speech quality is a multi-dimensional term and its evaluation contains several problems (Jekosh 1993, Mariniak 1993). The evaluation methods are usually designed to test speech quality in general, but most of them are suitable also for synthetic speech. It is very difficult, almost impossible, to say which test method provides the correct data. In a text-to-speech system not only the acoustic characteristics are important, but also text pre-processing and linguistic realization determine the final speech quality. Separate methods usually test different properties, so for good results more than one method should be used. And finally, how to assess the test methods themselves.
The evaluation procedure is usually done by subjective listening tests with response set of syllables, words, sentences, or with other questions. The test material is usually focused on consonants, because they are more problematic to synthesize than vowels. Especially nasalized consonants (/m/ /n/ /ng/) are usually considered the most problematic (Carlson et al. 1990). When using low bandwidth, such as telephone transmission, consonants with high frequency components (/f/ /th/ /s/) may sound very annoying. Some consonants (/d/ /g/ /k/) and consonant combinations (/dr/ /gl/ /gr/ /pr/ /spl/) are highly intelligible with natural speech, but very problematic with synthesized one. Especially final /k/ is found difficult to perceive. The other problematic combinations are for example /lb/, /rp/, /rt/, /rch/, and /rm/ (Goldstein 1995).
Some objective methods, such as Articulation Index (AI) or Speech Transmission Index (STI), have been developed to evaluate speech quality (Pols et al. 1992). These methods may be used when the synthesized speech is used through some transmission channel, but they are not suitable for evaluating speech synthesis in general. This is because there is no unique or best reference and with a TTS system, not only the acoustic characteristics are important, but also the implementation of a high-level part determines the final quality (Pols et al. 1992). However, some efforts have been made to evaluate objectively for example the quality of automatic segmentation methods in concatenative synthesis (Boeffard et al. 1993).
When repeating the test procedure to the same listening group, the test results may increase significally by the learning effect which means that the listeners get familiar with the synthetic speech they hear and they understand it better after every listening session (Neovius et al. 1993). Concentration problems, on the other hand, may decrease the results especially in segmental methods. Therefore, the decision of using naive or pro listeners in listening tests is important.
Several individual test methods for synthetic speech have been developed during last decades. Some researchers even complain that there are too many existing methods which make the comparisons and standardization procedure more difficult. On the other hand, there is still no test method to give undoubtedly the correct results. The most commonly used methods are introduced in this chapter. Also some computer softwares have been developed for making the test procedure easier to perform. One of these is for example the SAM SOAP (A Speech Output Assessment Package) which is implemented in PC-environment and contains several different test methods (Howard-Jones et al. 1991).
10.1 Segmental Evaluation Methods
With segmental evaluation methods only a single segment or phoneme intelligibility is tested. The very commonly used method to test the intelligibility of synthetic speech is the use of so called rhyme tests and nonsense words. The rhyme tests have several advantages (Jekosh 1993). The number of stimuli is reduced and the test procedure is not time consuming. Also naive listeners can participate without having to be trained and reliable results can be obtained with relatively small subject groups, which is usually from 10 to 20. The learning effects can also be discarded or measured. With these features the rhyme tests are easy and economic to perform. The obtained measure of intelligibility is simply the number of correctly identified words compared to all words and diagnostic information can be given by confusion matrices. Confusion matrices give information how different phonemes are misidentified and help to localize the problem points for development. However, rhyme tests have also some disadvantages. With monosyllabic words only single consonants are tested, the vocabulary is also fixed and public so the system designers may tune their systems for the test, and the listeners might remember the correct answers when participating in the test more than once. For avoiding these problems Jekosh (1992) has presented CLID-test described later in this chapter. Rhyme tests are available for many languages and they are designed for each language individually. The most famous segmental tests are the Diagnostic and Modified Rhyme Tests described below. Some developers or vendors, such as Bellcore and AT&T have also developed word lists for diagnostic evaluation of their own (Delogu et al 1995).
10.1.1 Diagnostic Rhyme Test (DRT)
The Diagnostic Rhyme Test, introduced by Fairbanks in 1958, uses a set of isolated words to test for consonant intelligibility in initial position (Goldstein 1995, Logan et al. 1989). The test consists of 96 word pairs which differ by a single acoustic feature in the initial consonant. Word pairs are chosen to evaluate the six phonetic characteristics listed in Table 10.1. The listener hears one word at the time and marks to the answering sheet which one of the two words he thinks is correct. Finally, the results are summarized by averaging the error rates from answer sheets. Usually, only total error rate percentage is given, but also single consonants and how they are confused with each other can be investigated with confusion matrices.
Table 10.1. The DRT characteristics.
|
Characteristics |
Description |
Examples |
|
Voicing |
voiced - unvoiced |
veal - feel, dense - tense |
|
Nasality |
nasal - oral |
reed - deed |
|
Sustension |
sustained - interrupted |
vee - bee, sheat - cheat |
|
Sibilation |
sibilated - unsibilated |
sing - thing |
|
Graveness |
grave - acute |
weed - reed |
|
Compactness |
compact - diffuse |
key - tea, show - sow |
DRT is a quite widely used method and it provides lots of valuable diagnostic information how properly the initial consonant is recognized and it is very useful as a developing tool. However, it does not test any vowels or prosodic features, so it is not suitable for any kind of overall quality evaluation. Other deficiency is that the test material is quite limited and the test items do not occur with equal probability, so it does not test all possible confusions between consonants. Thus, confusions presented as matrices are hard to evaluate (Carlson et al. 1990).
10.1.2 Modified Rhyme Test (MRT)
The Modified Rhyme Test, which is a sort of extension to the DRT, tests for both initial and final consonant apprehension (Logan et al. 1989, Goldstein 1995). The test consists of 50 sets of 6 one-syllable words which makes a total set of 300 words. The set of 6 words is played one at the time and the listener marks which word he thinks he hears on a multiple choice answer sheet. The first half of the words are used for the evaluation of the initial consonants and the second one for the final ones. Table 10.2 summarizes the test format (Shiga et al. 1994).
Table 10.2. Examples of the response sets in MRT.
|
|
A |
B |
C |
D |
E |
F |
|
1 |
bad |
back |
ban |
bass |
bat |
bath |
|
2 |
beam |
bead |
beach |
beat |
beak |
bean |
|
3 |
bus |
but |
bug |
buff |
bun |
buck |
|
... |
|
|
|
|
|
|
|
26 |
led |
shed |
red |
bed |
fed |
wed |
|
27 |
sold |
told |
hold |
fold |
gold |
cold |
|
28 |
dig |
wig |
big |
rig |
pig |
fig |
|
... |
|
|
|
|
|
|
Results are summarized as in DRT, but both final and initial error rates are given individually (Pisoni et al. 1980). Also same kind of problems are faced with MRT as with DRT.
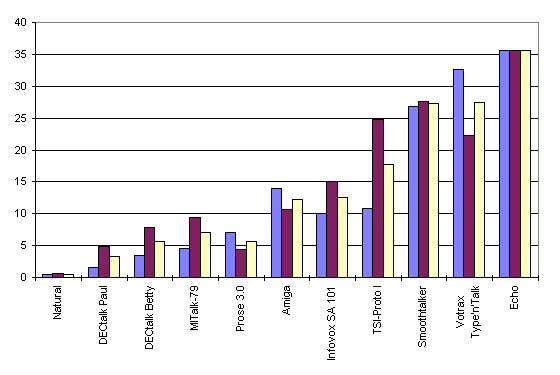
Logan et al. (1989) have presented this test for nine synthesizers and natural speech. They also performed an open response version of the test and found out that the intelligibility decreased significally when the multiple choice answer sheet is excluded. The results are summarized in Figure 10.1 where the three error rates for each synthesizer are shown for the initial consonants, the final consonants, and the average of these respectively. The test and the results are also summarized in Santen et al. (1997).
Fig. 10.1. The example of DRT (Logan et al. 1989).
10.1.3 Diagnostic Medial Consonant Test (DMCT)
Diagnostic Medial Consonant Test is same kind of test like rhyme tests described before. The material consists of 96 bisyllable word pairs like "stopper - stocker" which were selected to differ only with their intervocalic consonant. As in DRT, these differences are categorized into six distinctive features and score in each of these categories provides information on diagnosing system deficiencies. The listeners task is to choose correct word from two possible alternatives in the answer sheet. These scores are averaged together to provide an overall measure of system segmental intelligibility.
10.1.4 Standard Segmental Test
The SAM Standard Segmental Test (Jekosh 1993, Pols et al. 1992) uses lists of CV, VC, and VCV nonsense words. All consonants that can occur at the respective positions and three vowels /a/, /i/, and /u/ are the basic items of the test material. For each stimulus, the missing consonant must be filled to the response sheet, so the vowels are not tested at all. The test material is available and used for at least English, German, Swedish, and Dutch. Examples may be found for example in (Goldstein 1995).
10.1.5 Cluster Identification Test (CLID)
The Cluster Identification Test was developed under the ESPRIT project SAM (Jekosh 1992, 1993). The test is based on statistical approach. The test vocabulary is not predefined and it is generated for each test sequence separately. The test procedure consists of three main phases: word generator, phoneme-to-grapheme converter and an automatic scoring module. Word generator generates the test material in phonetic representation. The user can determine the number of words to be generated, the syllable structure (e.g., CCVC, VC,...), and the frequency of occurrence of cluster, initial, medial, and final cluster separately. Syllable structures can also be generated in accordance of their statistical distribution. For example, the structure CCVC occurs more often than CCCVCCC. Used words are usually nonsense. Since most of the synthesizers do not accept phoneme strings, the string has to be converted into graphemic representation. Finally, the error rates are automatically fetched from computer. Initial, medial, and final clusters are scored individually. Also confusion matrices for investigating mix-ups between certain phonemes are easy to generate from the data. In CLID test the open response answering sheet is used and the listener can use either a phonemic or a graphemic transcription. Used sound pressure level (SPL) can be also chosen individually (Kraft et al. 1995).
10.1.6 Phonetically Balanced Word Lists (PB)
In the Phonetically Balanced Word Lists the monosyllabic test words are chosen so that they approximate the relative frequency of phoneme occurrence in each language (Logan et al. 1989, Goldstein 1995). The first this kind of word list was developed in Harvard University during the Second World War. The relative difficulty of the stimulus items was constrained so that items that were always missed or always correct were removed, leaving only those items that provided useful information. The open response set was used. Several other balanced word lists have been developed (Goldstein 1995). For example, the Phonetically Balanced-50 word discrimination test (PB-50) consists of 50 monosyllabic words which approximates the relative frequency of occurrence in English. The PD-100 test is developed to compare for phonetic discrimination and for overall recognition accuracy. The test material includes examples of all possible consonants both in initial and final position and all vowels are in medial position.
10.1.7 Nonsense words and Vowel-Consonant transitions
The use of nonsense words (logotoms), mostly transitions between vowels (V) and consonant (C) is one of the most commonly used evaluation method for synthetic speech. This method provides high error rates and excellent diagnostic material especially when open response set is used. Usually a list of VC, CV, VCV or CVC words is used, but longer words, such as CVVC, VCCV, or CCCVCCC, are sometimes needed. Especially when testing diphone-based systems, longer units must be used to test all CV-, VC-, VV-, and CC-diphone-units. Test words are usually symmetric, like /aka/, /iki/, /uku/ or /kak/, /kik/, /kuk/. Common examples of these methods can be found for example in Carlson et al. (1990) and Dutoit et al. (1994).
Several sets of sentences have been developed to evaluate the comprehension of synthetic speech. Sentences are usually chosen to model the occurrence frequency of words in each particular language. Unlike in segmental tests, some items may be missed and the given answer may still be correct, especially if meaningful sentences are used (Pisoni et al. 1980, Allen et al. 1987).
10.2.1 Harvard Psychoacoustic Sentences
Harvard Psychoacoustic Sentences is a closed set of 100 sentences developed to test the word intelligibility in sentence context. The sentences are chosen so that the various segmental phonemes of English are represented in accordance with their frequency of occurrence. The test is easy to perform, no training of the subjects is needed and the scoring is simple. However, when using fixed set of sentences, the learning effect is very problematic (Pisoni et al. 1980, Kleijn et al. 1998). The first five sentences of the test material are (Allen et al. 1987):
Nevertheless the number of sentences is large, the subject may also be familiar with the test material without listening to it. For example, the first one of these sentences is used in many demonstrations or sound examples.
Haskins sentences are also developed to test the speech comprehension in sentence or word level. Unlike in Harvard sentences, the test material is anomalous which means that the missed items can not be concluded from context as easily as with use of meaningful sentences (Pisoni et al. 1980). As in Harvard sentences, a fixed set of sentences is used and due to learning effect the test subjects can be used only once for reliable results. The first five sentences of the test material are (Allen et al. 1987):
It is easy to see that these sentences are more difficult to perceive than Harvard sentences and they are not faced in real life situations.
10.2.3 Semantically Unpredictable Sentences (SUS)
The SUS-test is also an intelligibility test on sentence level (Goldstein 1995, Pols et al. 1992). The words to be tested are selected randomly from a pre-defined list of possible candidates. These are mostly mono-syllabic words with some expectations. The test contains five grammatical structures described with examples in Table 10.3 below. As in Haskins sentences, the missed item can not be concluded from textual context.
Table 10.3. Grammatical structures in SUS-test (Jekosh 1993).
|
|
Structure |
Example |
|
1 |
Subject - verb - adverbial |
The table walked through the blue truth. |
|
2 |
Subject - verb - direct object |
The strong way drank the day. |
|
3 |
Adverbial - verb - direct object |
Never draw the house and the fact. |
|
4 |
Q-word - transitive verb - subject - direct object |
How does the day love the bright word. |
|
5 |
Subject - verb - complex direct object |
The plane closed the fish that lived. |
In the actual test, fifty sentences, ten of each grammatical structure, are generated and played in random order to test subjects. If the test procedure is run more than once, a learning effect may be observed. But because the sentence set is not fixed, the SUS-test is not as sensitive to for example the learning effect as previously described test sentences.
Most of the test methods above are used to test how the single phoneme or word is recognized. In comprehension tests a subject hears a few sentences or paragraphs and answers to the questions about the content of the text, so some of the items may be missed (Allen et al. 1987). It is not important to recognize one single phoneme, if the meaning of the sentence is understood, so the 100% segmental intelligibility is not crucial for text comprehension and sometimes even long sections may be missed (Bernstein et al. 1980). No significant differences were obtained in understanding between natural and synthetic voice (Goldstein 1995). Only with prosody and naturalness the differences are perceptible which may also influence to the concentration of test subjects.
Evaluation of the prosodic features in synthesized speech is probably one of the most challenging tasks in speech synthesis quality evaluation. Prosody is also one of the least developed parts of existing TTS systems and needs considerable attention for the research in the future. For more discussion about prosody, see Chapter 5.
Prosodic features may be tested with test sentences which are synthesized with different emotions and speaker features. The listeners task is to evaluate for example with five level scale how well the certain characteristic in speech is produced. Evaluation may be made also by other kind of questions, such as "Does the sentence sound like a question, statement or imperative".
10.5 Intelligibility of Proper Names
With some proper names, such as Leicester, Edinburgh, or Begin, the correct pronunciation is usually almost impossible to find from written text. Places like Nice and Begin are also ambiguous when they are in the initial position of the sentence. For applications, such as automatic telephone directory inquiry service, the correct pronunciation of common names is very important. Unfortunately, almost infinite number of first- and surnames exist with many different versions of pronunciation. Without any special rules for names, the mispronunciation percent may be even 40 % (Belhoula 1993). With morphological analysis or pronunciation-by-analogy like methods described in chapter 5 it is possible to increase the speech intelligibility with common names considerably. With a large exception library it is possible to achieve even 90 % intelligibility.
10.6 Overall Quality Evaluation
Methods presented in this chapter are mostly developed for evaluating single features of speech quality. Several methods have been developed to evaluate speech quality in general and these methods are also suitable to measure overall quality or acceptability of synthetic speech (Klaus et al. 1993).
10.6.1 Mean Opinion Score (MOS)
Mean Opinion Score is probably the most widely used and simplest method to evaluate speech quality in general. It is also suitable for overall evaluation of synthetic speech. MOS is a five level scale from bad (1) to excellent (5) and it is also know as ACR (Absolute Category Rating). The listener's task is simply to evaluate the tested speech with scale described in Table 10.4 below. In the same table a kind of opposite version of MOS scale, so called DMOS (Degradation MOS) or DCR (Degradation Category Rating), is presented. DMOS is an impairment grading scale to measure how the different disturbances in speech signal are perceived.
Table 10.4. Scales used in MOS and DMOS.
|
|
MOS (ACR) |
DMOS (DCR) |
|
5 |
Excellent |
Inaudible |
|
4 |
Good |
Audible, but not annoying |
|
3 |
Fair |
Slightly annoying |
|
2 |
Poor |
Annoying |
|
1 |
Bad |
Very annoying |
However, the use of simple five level scale is easy and provides some instant explicit information, the method gives any segmental or selected information on which parts of the synthesis system should be improved (Goldstein 1995).
10.6.2 Categorical Estimation (CE)
In categorical estimation methods the speech is evaluated by several attributes or aspects independently (Kraft et al. 1995). Possible attributes may be like in Table 10.5 which are from Categorical Rating Test (CRT) performed by Kraft et al (1995) for five German synthesizers.
Table 10.5. Examples of possible attributes for Categorical Estimation.
|
Attribute |
Ratings |
|
pronunciation |
not annoying ... very annoying |
|
speed |
much too slow ... much too fast |
|
distinctness |
very clear ... very unclear |
|
naturalness |
very natural ... very unnatural |
|
stress |
not annoying ... very annoying |
|
intelligibility |
very easy ... very hard |
|
comprehensibility |
very easy ... very hard |
|
pleasantness |
very pleasant ... very unpleasant |
The method indicates well some individual strong and weak points in system and is easy to perform so it is useful for overall assessment of synthetic speech.
Pair comparison methods are usually used to test system overall acceptance (Kraft et al. 1995). An average listener of a speech synthesizer will listen to artificial speech for perhaps hours per day so the small and negligible errors may become very annoying because of their frequent occurrences. Some of this effect may be apparent if few sentences are frequently repeated in the test procedure (Kraft et al. 1995).
Stimuli from each synthesizer are compared in pairs with all n(n-1) combinations, and if more than one test sentence (m) is used each version of a sentence is compared to all the other version of the same sentence. This leads total number of n(n-1)m comparison pairs. The category "equal" is not allowed (Goldstein 1995).
10.6.4 Magnitude and Ratio Estimation
Magnitude and ratio estimation methods are used to make direct numerical estimate to the perceived sensory magnitudes produced by different stimuli, such as loudness and brightness. Nonsensory variables, such as emotional experience may also be used (Pavlovic et al. 1990). Unlike in pair comparison or categorical estimation, which use the interval scale, magnitude estimation method uses absolute ratio scale. In ratio estimation, a modulus or a standard stimulus is used with tested signal and in magnitude estimation, no modulus is given.
The most optimal way to test the suitably for individual application is to perform the test in a real environment. In that case the quality of the whole system, not only the speech quality, is usually tested. For example, when testing the reading machines with the optical scanner the overall quality is affected also by the quality of scanner and the text recognition software, or when using speech synthesis in telephony applications, the quality of telephone transmission line is very effective to the overall results. In some situations, it is not possible to perform the test in a real environment, because the environment is not known beforehand. Conditions may be very different for example over the telephone line, in the airplane cockpit or in the classroom.
As mentioned before, the visual information may increase the speech intelligibility significally (Beskow et al. 1997), especially with front vowels and labial consonants. Audiovisual speech is important especially in noisy environments. The intelligibility of audiovisual speech can be evaluated the same way as normal speech. It is also feasible to compare the results to other combinations of natural and synthetic face and speech. It is easy to see from Figure 10.2 that the intelligibility increases with facial information. The test results are based on test made by Beskow et al. (1997). The audio signal was degraded by adding white noise and the signal-to-noise ratio was 3 dB.
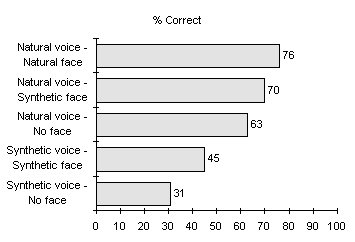
Fig. 10.2. Results from intelligibility tests (Beskow et al. 1997).
It is obvious that the highest improvement is achieved with bilabials and labiodentals. On the other hand, with palatal and velar consonants, there is no improvements to intelligibility due to back articulatory movements (Beskow et al. 1997, Le Goff et al. 1996).
Like presented in this chapter, synthesized speech can be evaluated by many methods and at several levels. All methods give some kind of information on speech quality, but it is easy to see that there is no test to give the one and only correct data. Perhaps the most suitable way to test a speech synthesizer is to select several methods to assess each feature separately. For example using segmental, sentence level, prosody, and overall tests together provides lots of useful information, but is on the other hand very time-consuming.
The test methods must be chosen carefully because there is no sense to have the same results from two tests. It is also important to consider in advance what kind of data is needed and why. It may be even reasonable to test the method itself with a very small listening group to make sure the method is reasonable and will provide desirable results.
The assessment methods need to be developed as well as speech synthesizers. Feedback from real users is essential and necessary to develop speech synthesis and the assessment methods.