9. Products
This chapter introduces some of the commercial products, developing tools, and ongoing speech synthesis projects available today. It is clear that it is not possible to present all systems and products out there, but at least the most known products are presented. Some of the text in this chapter is based on information collected from Internet, fortunately, mostly from the manufacturers and developers official homepages. However, some criticism should be bear in mind when reading the "this is the best synthesis system ever" descriptions from these WWW-sites.
First commercial speech synthesis systems were mostly hardware based and the developing process was very time-consuming and expensive. Since computers have become more and more powerful, most synthesizers today are software based systems. Software based systems are easy to configure and update, and usually they are also much less expensive than the hardware systems. However, a stand alone hardware device may still be the best solution when a portable system is needed.
The speech synthesis process can be divided in high-level and low-level synthesis. A low-level synthesizer is the actual device which generates the output sound from information provided by high-level device in some format, for example in phonetic representation. A high-level synthesizer is responsible for generating the input data to the low-level device including correct text-preprocessing, pronunciation, and prosodic information. Most synthesizers contain both, high and low level system, but due to specific problems with methods, they are sometimes developed separately.
9.1 Infovox
Telia Promotor AB Infovox speech synthesizer family is perhaps one of the best known multilingual text-to-speech products available today. The first commercial version, Infovox SA-101, was developed in Sweden at the Royal Institute of Technology in 1982. The system is originally descended from OVE cascade formant synthesizer (Ljungqvist et al. 1994). Several versions of current system are available for both software and hardware platforms.
The latest full commercial version, Infovox 230, is available for American and British English, Danish, Finnish, French, German, Icelandic, Italian, Norwegian, Spanish, Swedish, and Dutch (Telia 1997). The system is based on formant synthesis and the speech is intelligible but seems to have a bit of Swedish accent. The system has five different built-in voices, including male, female, and child. The user can also create and store individual voices. Aspiration and intonation features are also adjustable. Individual articulation lexicons can be constructed for each language. For words which do not follow the pronunciation rules, such as foreign names, the system has a specific pronunciation lexicon where the user can store them. The speech rate can be varied up to 400 words per minute. The text may be synthesized also word by word or letter by letter. Also DTMF tones can be generated for telephony applications. The system is available as a half length PC board, RS 232 connected stand-alone desktop unit, OEM board, or software for Macintosh and Windows environments (3.1, 95, NT) and requires only 486DX33MHz with 8 Mb of memory.
Telia has also recently introduced English, German, and Dutch versions of new and improved Infovox 330 software for Windows 95/NT environments. Other languages are under development and will be released soon. Unlike earlier systems, Infovox 330 is based on diphone concatenation of pre-recorded samples of speech. The new system is also more complicated and requires more computational load than earlier versions.
Digital Equipment Corporation (DEC) has also long traditions with speech synthesizers. The DECtalk system is originally descended from MITalk and Klattalk described earlier in Chapter 2. The present system is available for American English, German and Spanish and offers nine different voice personalities, four male, four female and one child. The present system has probably one of the best designed text preprocessing and pronunciation controls. The system is capable to say most proper names, e-mail and URL addresses and supports a customized pronunciation dictionary. It has also punctuation control for pauses, pitch, and stress and the voice control commands may be inserted in a text file for use by DECtalk software applications. The speaking rate is adjustable between 75 to 650 words per minute (Hallahan 1996). Also the generation of single tones and DTMF signals for telephony applications is supported.
DECtalk software is currently available for Windows 95/NT environments and for Alpha systems running Windows NT or DIGITAL UNIX. A software version for Windows requires at least Intel 486-based computer with 50 MHz processor and 8 Mb of memory. The software provides also an application programming interface (API) that is fully integrated with computer's audio subsystem. Three audio formats are supported, 16- and 8-bit PCM at 11 025 Hz sample rate for standard audio applications and 8-bit m -law encoded at 8 000 Hz for telephony applications (Hallahan 1996).
The software version has also three special modes, speech-to-wave mode, the log-file mode, and the text-to-memory mode. The speech-to-wave mode, where the output speech is stored into wav-file, is essential for slower Intel machines which are not able to perform real-time speech synthesis. The log-file mode writes the phonemic output in to file and the text-to-memory mode is used to store synthesized speech data into buffers from where the applications can use them (Hallahan 1996).
A hardware version of DECtalk is available as two different products, DECtalk PC2 and DECtalk Express. DECtalk PC2 is an internal ISA/EISA bus card for IBM compatible personal computers and uses a 10 kHz sample rate. DECtalk Express is an external version of the same device with standard serial interface. The device is very small (92 x 194 x 33 mm, 425 g) and so suitable for portable use. DECtalk speech synthesis is also used in well known Creative Labs Sound Blaster audio cards know as TextAssist. These have also a Voice editing tool for new voices.
The present DECtalk system is based on digital formant synthesis. The synthesizer input is derived from phonemic symbols instead of using stored formant patterns as in a conventional formant synthesizer (Hallahan 1996). The system uses 50 different phonemic symbols including consonants, vowels, diphthongs, allophones, and a silence. Symbols are based on the Arpabet phoneme alphabet which is developed to represent American English phonemes with normal ASCII characters. Also IPA symbols for American English are supported.
Digital is also developing a talking head called DECface (Waters et al. 1993). The system is a simple 2D representation of frontal view. The model consists of about 200 polygons mostly presenting mouth and teeth. The jaw nodes are moved vertically as a function of displacement of the corners of the mouth and the lower teeth are displacement along with the lower jaw. For better realism, the eyelid movements are also animated.
AT&T Bell Laboratories (Lucent Technologies) has also very long traditions with speech synthesis since the demonstration of VODER in 1939. The first full TTS system was demonstrated in Boston 1972 and released in 1973. It was based on articulatory model developed by Cecil Coker (Klatt 1987). The development process of the present concatenative synthesis system was started by Joseph Olive in mid 1970's (Bell Labs 1997). Present system is based on concatenation of diphones, context-sensitive allophonic units or even of triphones.
The current system is available for English, French, Spanish, Italian, German, Russian, Romanian, Chinese, and Japanese (Möbius et al. 1996). Other languages are under development. The development is focused primarily for American English language with several voices, but the system is multilingual in the sense that the software is identical for all languages, except English. Some language specific information is naturally needed, which is stored externally in separate tables and parameter files.
The system has also good text-analysis capabilities, as well as good word and proper name pronunciation, prosodic phrasing, accenting, segmental duration, and intonation. Bell Laboratories have particular activity for developing statistical methods for handling these problematic aspects. The latest commercial version for American English is available as several products, for example TrueTalk provided by Entropic Research and WATSON FlexTalk by AT&T.
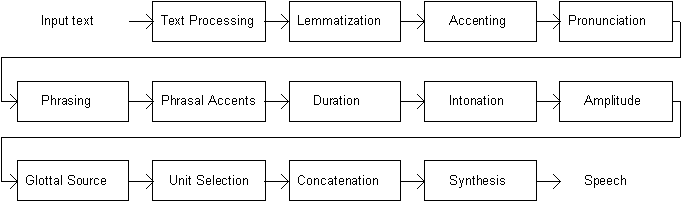
The architecture of the current system is entirely modular (Möbius et al. 1996). It is designed as pipeline presented in Figure 9.1 where each of 13 modules handle one particular step for the process. So members of a research group can work on different modules separately and an improved version of a given module can be integrated anytime as long as the communication between the modules and the structure of the information to be passed along is properly defined. Another advantage of this structure is that it is possible to interrupt and initiate processing anywhere in the pipeline and assess TTS information in that particular point, or to insert tools or programs to modify TTS parameters.
Fig. 9.1. Modules of the English TTS system.
The text processing module handles the end-of-the-sentence detection, text normalization (expansion of numbers, abbreviations etc.), and makes some grammatical analysis. The Accenting module handles the assignment of levels of prominence to various words in the sentence. The pronunciation module handles the pronunciation of words and names and the disambiguation of homographs. The phrasing module contains the breaking of long stretches of text into one or more intonational units. The duration determines the appropriate segmental durations for phonemes in the input on the basis of linguistic information. Intonation module computes the fundamental frequency contour. The glottal source determines the parameters of the glottal source (glottal open quotient, spectral tilt, and aspiration noise) for each sentence. The unit selection module handles the selection of appropriate concatenative units given the phoneme string to be synthesized. Finally, the selected units are concatenated and synthesized (Santen et al. 1997).
Bell Laboratories are also developing an Internet Speech Markup Language with CSTR. The main objective is to combine the present Internet Markup Languages into a single standard.
Laureate is a speech synthesis system developed during this decade at BT Laboratories (British Telecom). To achieve good platform independence Laureate is written in standard ANSI C and it has a modular architecture shown in Figure 9.2 below (Gaved 1993, Morton 1987). The Laureate system is optimized for telephony applications so that lots of attention have been paid for text normalization and pronunciation fields. The system supports also multi-channel capabilities and other features needed in telecommunication applications.
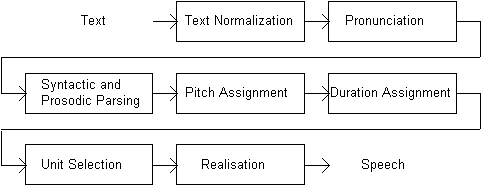
Fig. 9.2. Overview of Laureate.
The current version of Laureate is available only for British and American English with several different accents. Prototype versions for French and Spanish also exist and several other European languages are under development. A talking head for the system has been also recently introduced (Breen et al. 1996). More information, including several pre-generated sound examples and interactive demo, is available at the Laureate home page (BT Laboratories 1998).
SoftVoice, Inc. has over 25 years of experience in speech synthesis. It is known for SAM (Software Automatic Mouth) synthesizer for Commodore C64 (SAM-synthesizer) and Amiga (Narrator), Apple (original MacinTalk), and Atari computers in the early 1980's which were probably the first commercial software based systems for personal home computers.
The latest version of SVTTS is the fifth generation multilingual TTS system for Windows is available for English and Spanish with 20 preset voices including males, females, children, robots, and aliens. Languages and parameters may be changed dynamically during speech. More languages are under development and the user may also create an unlimited number of own voices. The input text may contain over 30 different control commands for speech features. Speech rate is adjustable between 20 and 800 words per minute and the fundamental frequency or pitch between 10 and 2000 Hz. Pitch modulation effects, such as vibrato, perturbation, and excursion, are also included. Vocal quality may be set as normal, breathy, or whispering and the singing is also supported. The output speech may be also listened in word-by-word or letter-by-letter modes. The system can also return mouth shape data for animation and has capable to send synchronization data for the other user's applications. The basic architecture of the present system is based on formant synthesis.
The speech quality of SoftVoice is not probably the best of the available products, but with the large number of control characters and different voices makes it very useful for several kinds of multimedia applications.
One of the most promising methods for concatenation synthesis was introduced in mid 1980's by France Telecom CNET (Centre National d'Etudes Télécommunications). The synthesizer is a diphone based synthesizer which uses the famous PSOLA algorithm discussed earlier in chapter 5.
The latest commercial product is available from Elan Informatique as ProVerbe TTS system. The concatenation unit used is diphone sampled at 8 kHz rate. The ProVerbe Speech Unit is a serial (RS232 or RS458) connected external device (150x187x37 mm) optimized for telecommunication applications like e-mail reading via telephone. The system is available for American and British English, French, German, and Spanish. The pitch and speaking rate are adjustable and the system contains a complete telephone interface allowing connection directly to the public network. ProVerbe has also an ISA connected internal device which is capable also multichannel operation. Internal device is available also for Russian language and has same features as serial unit.
ORATOR is a TTS system developed by Bell Communications Research (Bellcore). The synthesis is based on demisyllable concatenation (Santen 1997, Macchi et al. 1993, Spiegel 1993). The latest ORATOR version provides probably one of the most natural sounding speech available today. Special attention on text processing and pronunciation of proper names for American English is given and the system is thus suitable for telephone applications. The current version of ORATOR is available only for American English and supports several platforms, such as Windows NT, Sun, and DECstations.
Eurovocs is a text-to-speech synthesizer developed by Technologie & Revalidatie (T&R) in Belgium. It is a small (200 x 110 x 50 mm, 600g) external device with built-in speaker and it can be connected to any system or computer which is capable to send ASCII via standard serial interface RS232. No additional software on computer is needed. Eurovocs system uses the text-to-speech technology of Lernout and Hauspie speech products described in the following chapter, and it is available for Dutch, French, German, Italian, and American English. One Eurovocs device can be programmed with two languages. The system supports also personal dictionaires. Recently introduced improved version contains also Spanish and some improvements in speech quality and device dimensions have been made.
Lernout & Hauspies (L&H) has several TTS products with different features depending on the markets they are used. Different products are available optimized for application fields, such as computers and multimedia (TTS2000/M), telecommunications (TTS2000/T), automotive electronics (TTS3000/A), consumer electronics (TTS3000/C). All versions are available for American English and first two also for German, Dutch, Spanish, Italian, and Korean (Lernout & Hauspie 1997). Several other languages, such as Japanese, Arabic, and Chinese are under development. Products have a customizable vocabulary tool that permits the user to add special pronunciations of words which do not succeed with normal pronunciation rules. With a special transplanted prosody tool it is possible to copy duration and intonation values from recorded speech for commonly used sentences which may be used for example in information and announcement systems.
Recently, a new version for PC multimedia (TTS3000/M) has been introduced for Windows 95/NT with Software Developer's kit (API) and a special E-mail preprocessing software. The E-mail processing software is capable to interpret the initials and names in addresses and handle the header information. The new version contains also Japanese and supports run-time switching between languages. System supports wav-formats with 8 kHz and 11 kHz. The architecture is based on concatenation of rather long speech segments, such as diphones, triphones, and tetraphones.
9.10 Apple Plain Talk
Apple has developed three different speech synthesis systems for their MacIntosh Personal Computers. Systems have different level of quality for different requirements. The PlainTalk products are available for MacIntosh computers only and they are downloadable free from Apple homepage.
MacinTalk2 is the wavetable synthesizer with ten built-in voices. It uses only 150 kilobytes of memory, but has also the lowest quality of PlainTalk family, but runs in almost every Macintosh system.
MacinTalk3 is a formant synthesizer with 19 different voices and with considerably better speech quality compared to MacinTalk2. MacinTalk3 supports also singing voices and some special effects. The system requires at least Macintosh with a 68030 processor and about 300 kb of memory. MacinTalk3 has the largest set of different sounds.
MacinTalkPro is the highest quality product of the family based on concatenative synthesis. The system requirements are also considerably higher than in other versions, but it has also three adjustable quality levels for slower machines. Pro version requires at least 68040 PowerPC processor with operating system 7.0 and uses about 1.5 Mb of memory. The pronunciations are derived from a dictionary of about 65,000 words and 5,000 common names.
AcuVoice is a software based concatenative TTS system (AcuVoice 1997). It uses syllable as a basic unit to avoid modeling co-articulation effects between phonemes. Currently the system has only American English male voice, but female voice is promised to release soon. The database consists of over 60 000 speech fragments and requires about 150 Mb of hard disk space. The memory requirement is about 2.7 Mb. The system supports personal dictionaries and allows also the user to make changes to the original database. A dictionary of about 60 000 proper names is also included and names not in the dictionary are produced by letter-to-sound rules which models how humans pronounce the names which are unfamiliar to them. Additions and changes to the dictionary are also possible. The maximum speech rate is system speed dependent and is at least over 20 words per minute. The output of the synthesizer may also be stored in 8- or 16-bit PCM file.
AcuVoice is available as two different products, AV1700 for standard use and AV2001 multichannel developer's kit which is also MS-SAPI compliant. The products are available for Windows 95/NT environments with 16-bit sound card, and for Solaris x86 and SPARC UNIX workstations.
CyberTalk is a software based text-to-speech synthesis system for English developed by Panasonic Technologies, Inc. (PTI), USA (Panasonic 1998). The system is a hybrid formant/concatenation system which uses rule-based formant synthesis for vowels and sonorants, and prerecorded noise segments for stops and fricatives. Numbers and some alphanumerical strings are produced separately with concatenation synthesis. The CyberTalk software is available for MS Windows with male and female voices. The sound engine requires 800 kb of memory and the speech data from 360 kb to 3.5 Mb depending on voice configuration. The system has over 100,000 words built-in lexicon and separate customizable user lexicon.
9.13 ETI Eloquence
ETI Eloquence is a software based TTS system developed by Eloquent Technology, Inc., USA, and is currently available for British and American English, Mexican and Castillian Spanish, French, German, and Italian. Other languages, such as Chinese are also under development. For each language the system offers seven built-in voices including male, female, and child. All voices are also easily customizable by user. The system is currently available for Windows95/NT requiring at least 468 processor at 66 MHz and 8 Mb of memory, and for IBM RS/6000 workstations running AIX.
Adjustable features are gender, head size, pitch baseline, pitch fluctuation, roughness, breathiness, speech, and volume. The head size is related to the vocal tract size, low pitch fluctuation produces a monotone sounding voice and a high breathiness value makes the speech sound like a whisper.
The architecture consists of three main modules, the text module, the speech module, and the synthesizer. The text module has components for text normalization and parsing. The speech module uses the information from text module to determine parameter values and durations for the synthesizer. Speech is synthesized with Klatt-style synthesizer with few modifications (Herz 1997).
One special feature in the system is different text processing modes, such as math mode which converts the number 1997 as one-thousand-ninety-seven instead of nineteen-ninety-seven and several spelling modes, such as radio mode which converts the input string abc as alpha, bravo, charlie. The system also supports customized dictionaries where the user can add special words, abbreviations and roots for overriding the default pronunciation. The system can handle common difficulties with compound words, such as the th between words hothouse and mother and with common abbreviations, such as St. (saint or street).
The system contains also several control symbols for emphasizing a particular word, expressing boredom or excitement, slow down or speed up, switch voices and even languages during the sentence. Virtually any intonation pattern may be generated.
The Festival TTS system was developed in CSTR at the University of Edinburgh by Alan Black and Paul Taylor and in co-operation with CHATR, Japan. The current system is available for American and British English, Spanish, and Welsh. The system is written in C++ and supports residual excited LPC and PSOLA methods and MBROLA database. With LPC method, the residuals and LPC coefficients are used as control parameters. With PSOLA or MBROLA the input may be for example standard PCM files (Black et al. 1997). As a University program the system is available free for educational, research, and individual use. The system is developed for three different aspects. For those who want simply use the system from arbitrary text-to-speech, for people who are developing language systems and wish to include synthesis output, such as different voices, specific phrasing, dialog types and so on, and for those who are developing and testing new synthesis methods.
The developers of Festival are also developing speech synthesis markup languages with Bell Labs and participated development of CHATR generic speech synthesis system at ATR Interpreting Telecommunications Laboratories, Japan. The system is almost identical to Festival, but the main interests are in speech translation systems (Black et al. 1994).
9.15 ModelTalker
ASEL ModelTalker TTS system is under development at University of Delaware, USA. It is available for English with seven different emotional voices, neutral, happy, sad, frustrated, assertive, surprise, and contradiction. English female and child voices are also under development. The system is based on concatenation of diphones and the architecture consists of seven largely independent modules, text analysis, text-to-phoneme rules, part of speech rules, prosodic analysis, discourse analysis, segmental duration calculation, and intonational contour calculation.
The MBROLA project was initiated by the TCTS Laboratory in the Faculté Polytechnique de Mons, Belgium. The main goal of the project is to develop multilingual speech synthesis for non-commercial purposes and increase the academic research, especially in prosody generation. It is a method like PSOLA, but named MBROLA, because of PSOLA is a trademark of CNET. The MBROLA-material is available free for non-commercial and non-military purposes (Dutoit et al. 1993, 1996).
The MBROLA v2.05 synthesizer is based on diphone concatenation. It takes a list of phonemes with some prosodic information (duration and pitch) as input and produces speech samples of 16 bits at the sampling frequency of the diphone database currently used, usually 16 kHz. It is therefore not a TTS system since it does not accept raw text as input, but it may be naturally used as a low level synthesizer in a TTS system. The diphone databases are currently available for American/British/Breton English, Brazilian Portuguese, Dutch, French, German, Romanian, and Spanish with male and/or female voice. Several other languages, such as Estonian, are also under development.
The input data required by MBROLA contains a phoneme name, a duration in milliseconds, and a series of pitch pattern points composed of two integers each. The position of the pitch pattern point within the phoneme in percent of its total duration, and the pitch value in Hz at this position. For example, the input "_ 51 25 114" tells the synthesizer to produce a silence of 51 ms, and to put a pitch pattern point of 114 Hz at 25% of 51ms.
9.17 Whistler
Microsoft Whistler (Whisper Highly Intelligent Stochastic TaLkER) is a trainable speech synthesis system which is under development at Microsoft Research, Richmond, USA. The system is designed to produce synthetic speech that sounds natural and resembles the acoustic and prosodic characteristics of the original speaker and the results have been quite promising (Huang et al. 1996, Huang et al. 1997, Acero 1998). The speech engine is based on concatenative synthesis and the training procedure on Hidden Markov Models (HMM). The speech synthesis unit inventory for each individual voice is constructed automatically from unlabeled speech database using the Whisper speech recognition system (Hon et al. 1998). The use of speech recognition for labeling the speech segments is perhaps the most interesting approach for this, usually time-consuming task in concatenative synthesis. The text analysis component is derived from Lernout & Hauspie's TTS engine and, naturally, the speech engine supports MS Speech API and requires less than 3 Mb of memory.
9.18 NeuroTalker
The INM (International Neural Machines, Canada) NeuroTalker is a TTS system with OCR (Optical Character Recognition) for American English with plans to release the major EU languages soon (INM 1997). The system allows the user to add specialized pronounced words and pronunciation rules to the speech database. The system recognizes most of the commonly used fonts, even when mixed or bolded. It is also capable to separate text from graphics and make corrections to text which can not be sometimes easily corrected through an embedded speller, such as numbers or technical terms. The system requires at least Intel 486DX with 8 Mb of memory and support most scanners available. The NeuroTalker is available as two products, the standard edition with normal recognition and synthesis software, and an audiovisual edition for the visually impaired.
9.19 Listen2
Listen2 is a text-to-speech system from JTS Microconsulting Ltd., Canada, which uses the ProVoice speech synthesizer. The current system is available as an English and international version. The English version contains male and female voices and the international version also German, Spanish, French, and Italian male voices. The languages may be switched during speech and in English version the gender and pitch may be changed dynamically. The speech output may also be stored in a separate wav-file. The system requires at least a 486-processor with 8 Mb of memory and a 16-bit sound card. The system has special e-mail software which can be set to announce for incoming mail with subject and sender information. The speech quality of Listen2 is far away from the best systems, but it is also very inexpensive.
SPRUCE (SPeech Response from UnConstrained English) is a high-level TTS system, currently under development at Universities of Bristol and Essex. The system is capable of creating parameter files suitable for driving most of the low-level synthesizers, including both formant and concatenation systems. A parallel formant synthesizer is usually used, because it gives more flexibility than other systems (Tatham et al. 1992a). In general, the system is capable to drive any low-level synthesizer based on diphones, phonemes, syllables, demi-syllables, or words (Lewis et al 1993). The system is successfully used to drive for example the DECtalk, Infovox, and CNET PSOLA synthesizers (Tatham et al. 1992b, 1995, 1996).
SPRUCE architecture consists of two main modules which are written in standard C. The first on is a module for phonological tasks which alter the basic pronunciation of an individual word according to its context, and the second is a module for prosodic task which alters the fundamental frequency and duration throughout the sentence (Lewis et al. 1997).
The system is based on inventory of syllables obtained from recorded natural speech to build the correct output file. The set of syllables is about 10 000 (Tatham et al. 1996). The top level of the system is dictionary based where the pronunciation of certain words are stored for several situations. For example, in weather forecast the set of used words is quite limited and consists of lots of special concepts, and with announcement systems the vocabulary may be even completely fixed. The word lexicon consists of 100 000 words which requires about 5 Mb disk space (Lewis et al. 1997).
HADIFIX (HAlbsilben, DIphone, SufFIXe) is a TTS system for German developed at University of Bonn, Germany. The system is available for both male and female voices and supports control parameters, such as duration, pitch, word prominence and rhythm. Inserting of pauses and accent markers into the input text and synthesis of singing voice are also supported.
The system is based on concatenation of demisyllables, diphones, and suffixes (Portele et al. 1991, 1992). First, the input text is converted into phonemes with stress and phrasing information and then synthesized using different units. For example, the word Strolch is formed by concatenating Stro and olch.
The concatenation of two segments is made by three methods. Diphone concatenation is suitable when there is some kind of stable part between segments. Hard concatenation is the simplest case of putting samples together with for example glottal stops. This also happens at each syllable boundary in demisyllable systems. Soft concatenation takes place at the segment boundaries where the transitions must be smoothed by overlapping (Portele et al. 1994).
The inventory structure consists of 1080 units (750 for initial demisyllables, 150 for diphones, and 180 for suffixes) which is sufficient to synthesize nearly all German words including uncommon sound combinations originating from foreign languages (Portele et al. 1992).
SVOX is a German text-to-speech synthesis system which has been developed at TIK/ETHZ (Swiss Federal Institute of Technology, Zurich). The SVOX system consists of two main modules. The transcription module includes the text analysis and the phonological generation which are speaker and voice independent. Phonological representation is generated from each input sentence and it includes the respective phoneme string, the accent level per syllable, and the phrase boundaries (position, type, and strength). The second one, phono-acoustical module, includes all the speaker-dependent components that are required to generate an appropriate speech signal from the phonological representation (Pfister 1995).
SYNTE2 was the first full text-to-speech system for Finnish and it was introduced in 1977 after five years of research in Tampere University of Technology (Karjalainen et al. 1980, Laine 1989). The system is a portable microprocessor based stand-alone device with analog formant synthesizer. The basic synthesis device consists of a Motorola 68000 microprocessor with 2048 bytes of ROM and 256 bytes of RAM, a set of special D/A-converters to generate analog control signals, and an analog signal processing part for sound generation, which is a combination of cascade and serial type formant synthesizers. SYNTE2 takes an ASCII string as input and some special characters may be used to control features, such as speech rate, intonation, and phoneme variation (Karjalainen et al. 1980). The information hierarchy of SYNTE2 is presented in Figure 9.3. More detailed discussion of SYNTE2 see (Karjalainen 1978), (Karjalainen et al. 1980), or (Laine 1989).
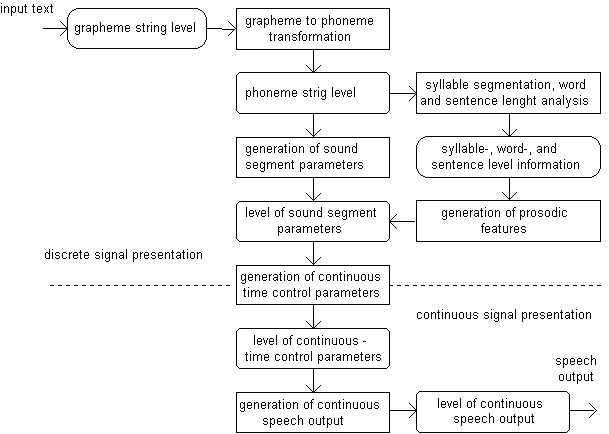
Fig. 9.3. SYNTE2 as an information hierarchy.
An improved version, SYNTE3, was introduced about five years later. The synthesis was based on a new parallel-cascade (PARCAS) model which is described earlier in Chapter 5 and more closely by Laine (1989). The speech quality was slightly improved and the commercial version system is still use.
Mikropuhe is a speech synthesizer for Finnish developed by Timehouse Inc. It is currently available for Windows 95/NT and Macintosh computers with one Finnish male voice. Also robotic and Donald Duck voices are available. Several other voices including female voice are under development. The synthesis is based on the microphonemic method concatenating about 10 ms long samples uttered from natural speech. The system uses 22050 Hz sampling frequency with 16 bits, but it works also with 8 bit sound cards.
The controllable features are the speech rate, the pitch, the pitch randomness, the peacefulness, and the duration of pauses between words. The speech rate can be adjusted between about 280 to 3200 characters per minute. The pitch can be set between 25 Hz and 300 Hz and the randomness up to 48 %. The duration of pauses between words can be set up to one second. The latest version of Mikropuhe (4.11) is available only for PC environments and it contains also singing support. All features can be also controlled by control characters within a text. The system also supports a personal abbreviation list with versatile controls and the output of the synthesizer can be stored into a separate wav-file.
Sanosse synthesis has been developed originally for educational purposes for the University of Turku. The system is based on concatenative synthesis and it is available for Windows 3.1/95/NT environments. The adjustable features are the speech rate, word emphasis, and the pauses between words. The input text can also be synthesized letter-by-letter, word-by-word, or even syllable-by-syllable. The feature can also be controlled with control characters within a text. Sanosse synthesis is currently use in aLexis software which is developed for computer based training for reading difficulties (Hakulinen 1998). The original Sanosse system is also adopted by Sonera for their telephony applications.
The product range of text-to-speech synthesizers is very wide and it is quite unreasonable to present all possible products or systems available out there. Hopefully, most of the famous and commonly used products are introduced in this chapter. Most products described here are also demonstrated on the accompanying audio CD described in Appendix A. Some of the currently available speech synthesis products are summarized in Appendix B.